

Při analýze klíčových slov musíte téměř vždy řešit následující dva problémy:
- duplicitní klíčová slova – týká se především případů, kdy dáváte dohromady klíčová slova z více zdrojů, ale stačí jeden nástroj, který vám prostě některá klíčová slova zobrazuje opakovaně (Nástroj pro návrh klíčových slov v Skliku)
- různé tvary klíčových slov – typicky např. s diakritikou a bez
Naším cílem dnes bude zajistit odstranění duplicit a sjednocení různých tvarů. Použijeme k tomu OpenRefine (dříve Google Refine) – jedná se o silný nástroj, se kterým je dobré se postupně sžít, takže mu dáme přednost přes Excelem a jinými nástroji.
Na konci článku najdete tahák pro nás zapomnětlivé.
Instalace OpenRefine
Stačí si zde vybrat balík vhodný pro vaši platformu. Instalace nebývá složitá – používám elementary OS, kde stačilo balík rozbalit a spustit ./refine v terminálu. Pro Windows je nejspíš ke stažení nějaký .exe soubor, který by se měl o vše postarat.
Program běží na vašem PC a ovládá se přes prohlížeč – stačí po spuštění do adresního řádku zadat http://127.0.0.1:3333
Import dat a vytvoření projektu
Abyste mohli s daty pracovat, nejdřív si je tam musíte importovat a vytvořit si první projekt. Pro naše potřeby budeme používat soubor s testovacími daty. Obsahuje na každém řádku jedno klíčové slovo a údaj o hledanosti. Pro jednoduchou neobsahuje žádné další údaje.
Krok #1: Klikněte na “Create project” (Vytvořit projekt). Data můžete importovat z URL adresy, schránky apod. My zvolíme lokální soubor (“This computer”).
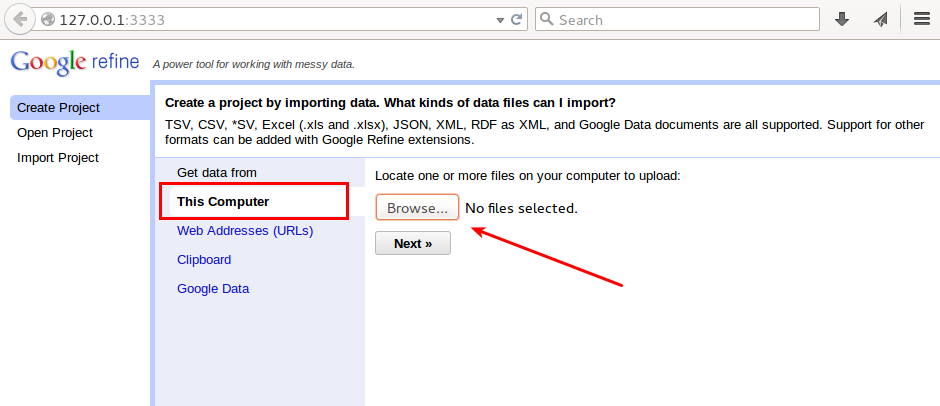
Krok #2: Zkontrolujte, zdali se data importovala v pořádku. Pokud je vše OK, můžete vpravo nahoře projekt pojmenovat a kliknout na “Create Project” (Vytvořit projekt).
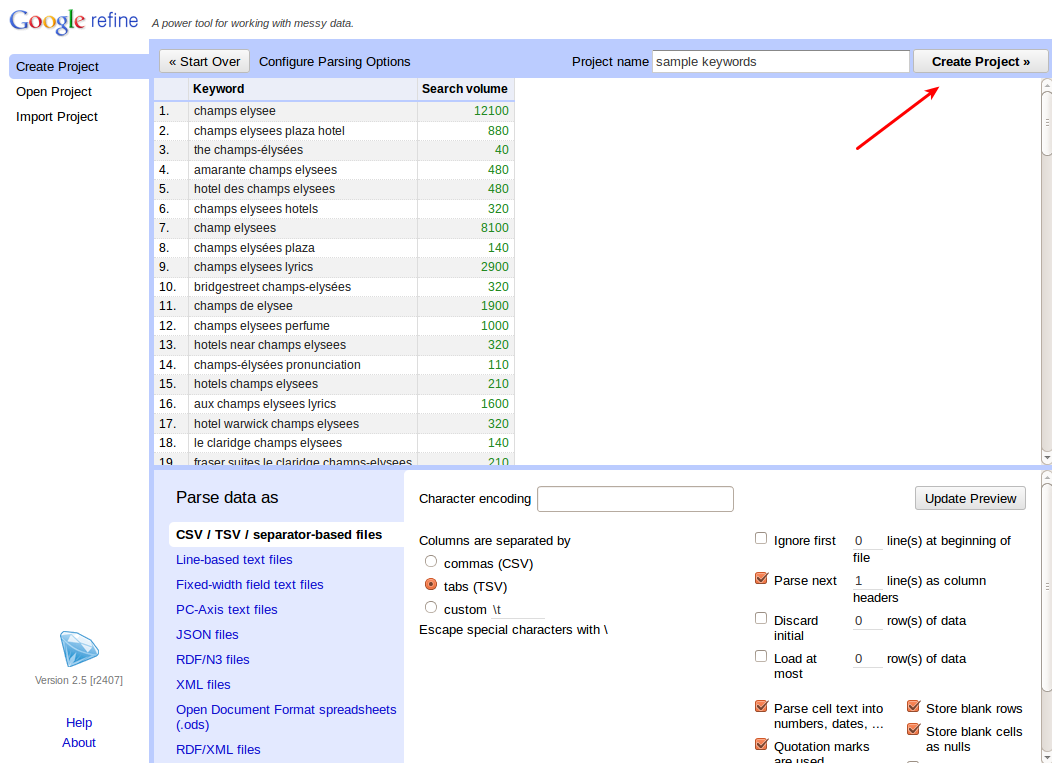
Krok #3: Předtím, než se pustíme do boje s duplicitami, musíme seznam seřadit podle klíčového slova. To provedeme přes malý modrý čtvereček u sloupce s klíčovými slovy, zvolíme Sort (“Řadit”) s vybereme řazení podle textu od A do Z.
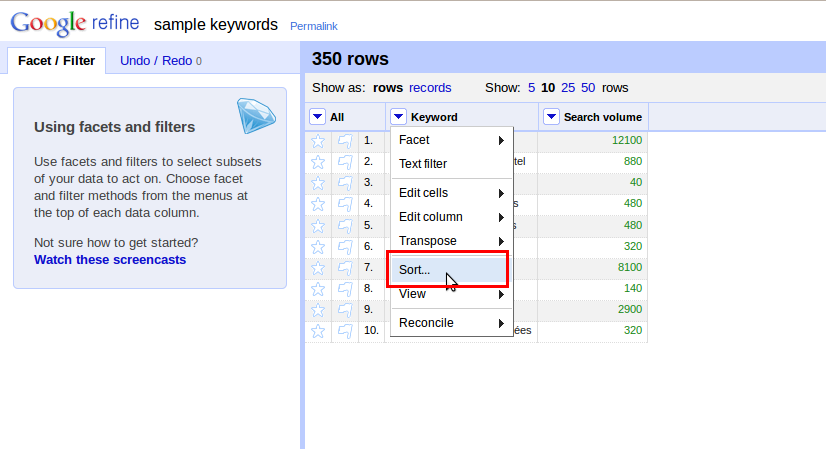
Trochu více vpravo se nám objevila nová nabídka “Sort” (Řadit), kde zvolíme “Reorder rows permanently” (Trvale změnit pořadí).
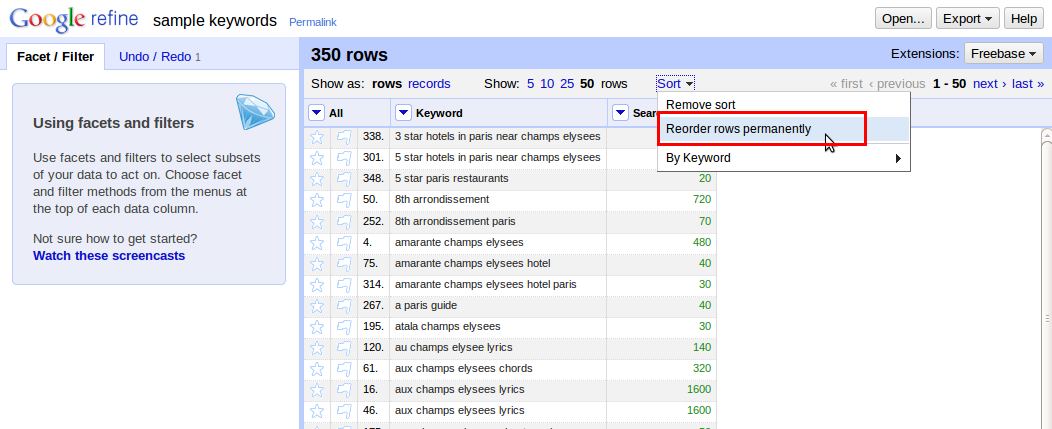
Krok #4: Nyní již máme data připravena a můžeme začít přímo s odstraněním duplicit. V nabídce (modrá šipka) u sloupce s klíčovými slovy zvolíme “Edit cells -> Blank down” (Editovat buňky -> Vymazat následující). Tím zajistíme, že jsou duplicitní klíčová slova vymazána. Zůstalo nám tu ale několik prázdných řádků.
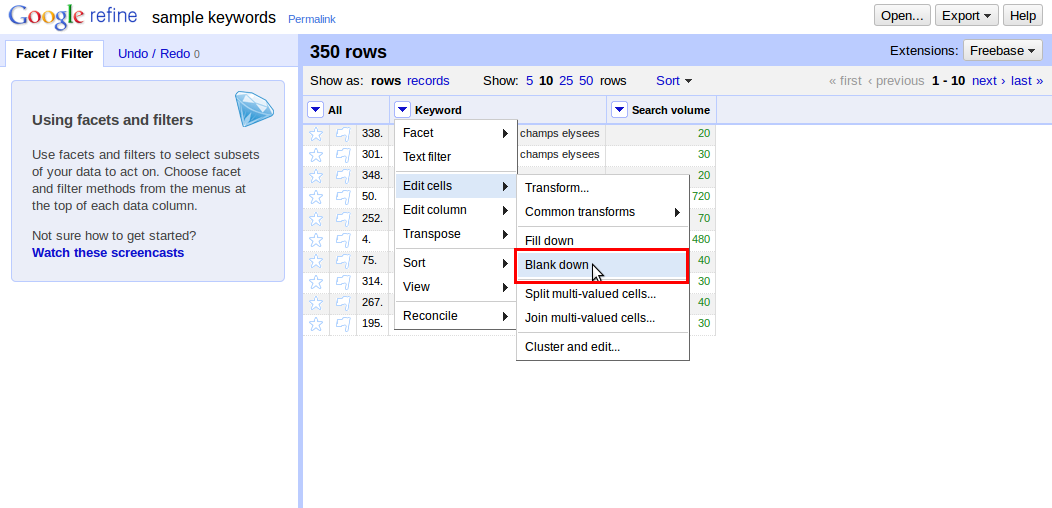
Krok #5: Prázdné řádky identifikujeme tak, že dáme opět nabídku u sloupce klíčových slov a zvolíme “Facet -> Text facet” (vsuvka: jak se překládá facet, je to toto?).
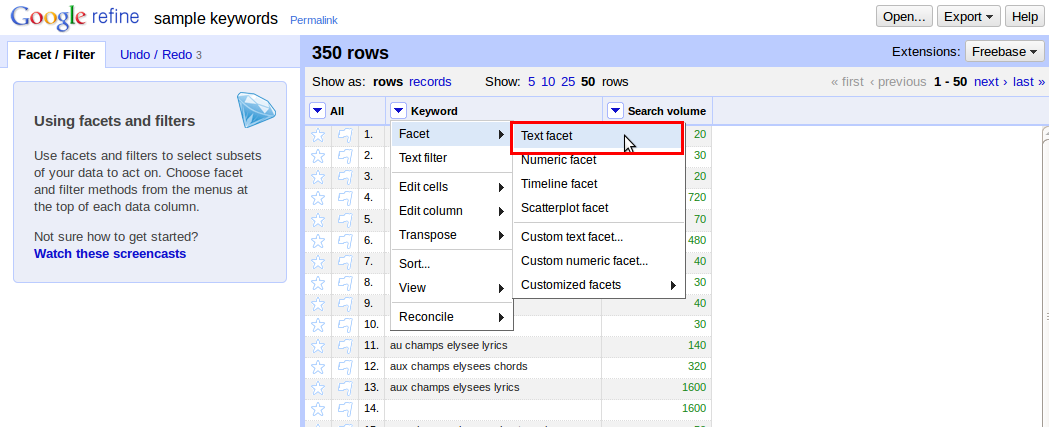
Vlevo přibylo pole v části “Facet / Filter”. Najdeme řádek (blank) a označíme jej. Ze seznamu klíčových slov jsou odfiltrována jen ta prázdná. Nyní je zvolíme “All -> Edit rows -> Remowe all matching rows” (Všechny -> Editovat řádky -> Odstranit všechny odpovídající řádky).
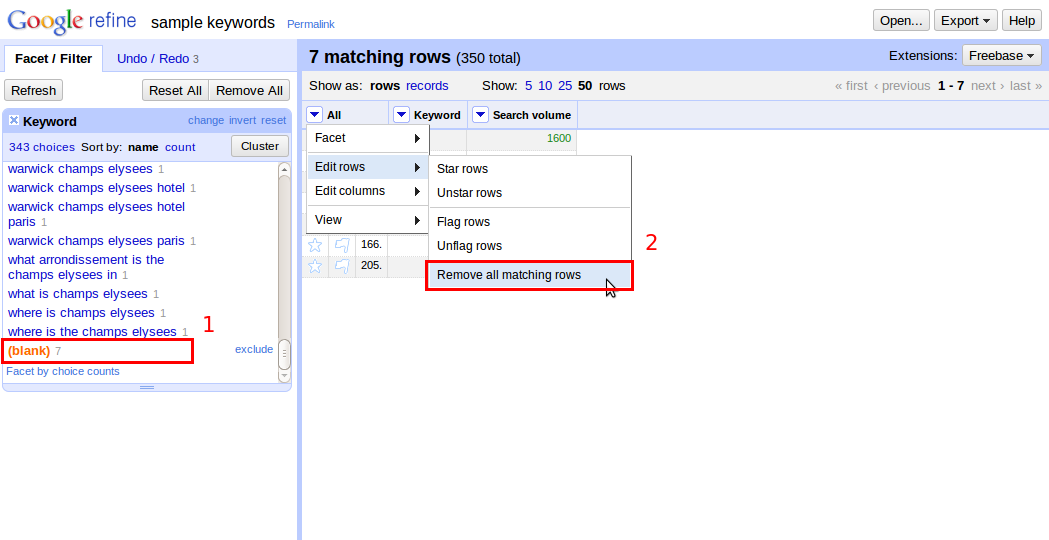
OK, duplicity jsou pryč. Máte pravdu: v Google Docs či LibreOffice by to bylo trochu rychlejší, ale to důležité teprve následuje.
Sjednocení různých variant klíčových slov
Krok #6: Nejprve si křížkem vlevo zavřete Facet, abyste zase viděli všechna klíčová slova. V nabídce u sloupce s klíčovými slovy zvolte “Edit cells -> Cluster and Edit” (Editovat buňky -> Sdružit a editovat).
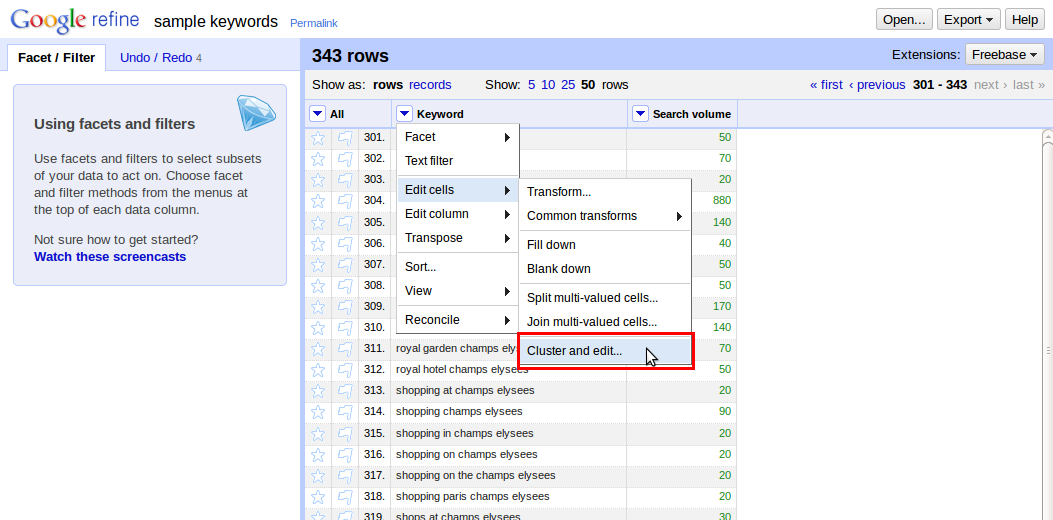
Zobrazí se vám nabídka viz obrázek níže. Standardní nastavení metody na “key collision” a keying function na “fingerprint” bývají často nejlepší, ale zkuste si s nastavením pohrát a ideálně provést sjednocení několikrát s různým nastavením (pro snížení chyby).
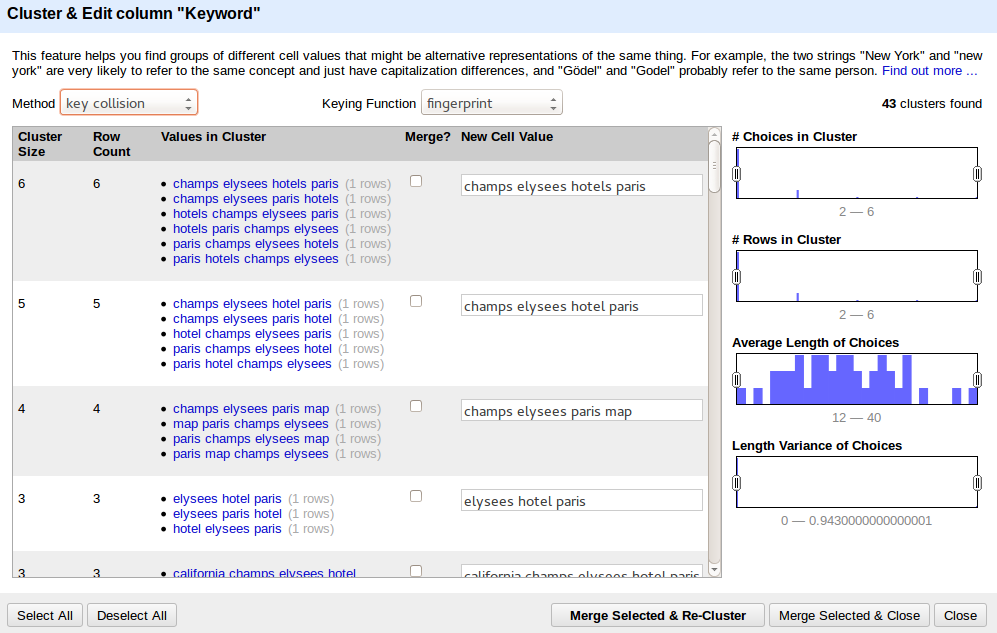
Krok #7: A můžeme sjednocovat. Stačí ve sloupci “Values in Cluster” zvolit ten tvar, který považujete za nejlepší (ten se správnou diaktritikou apod.) Případně můžete do “New Cell Value” (Nová hodnota buňky) dopsat vlastní hodnotu. Po najetí na skupinu klíčových slov se vám objeví odkaz “Browse this cluster” (Prohlížet tuto skupinu) – ten v novém okně zobrazí jen řádky v této skupině. Můžete tak zkontrolovat hledanost jednotlivých klíčových slov a další hodnoty a podle toho vybrat primární slovo pro skupinu.
Následně stačí kliknout na “Merge Selected & Re-Cluster” (Sjednotit označené a znovu seskupit). Nyní můžete zkusit aplikovat jinou metodu a “Keyring function” a sjednocení provést ještě jednou (nebo několikrát).
Teď jsme dosáhli toho, že je v každé sjednocené skupině použito jedno klíčové slov. Tím nám vznikla zase spousta duplicit, jenže návod výše nelze použít – nechceme tyto duplicity pouze odstranit, ale zároveň je u nich potřeba sečíst hodnotu hledanosti.
Krok #8: Postup je následující: Seřazení položek podle sloupce s klíčovým slovem (nabídka pod modrou šipkou -> Sort -> Sort…), poté nabídka Sort -> Reorder rows permanently.
Poté dáte znovu modrou šipku u sloupce s klíčovým slovem a nyní zvolíte Edit cells -> Blank down. Uvidíte něco jako obrázek níže:
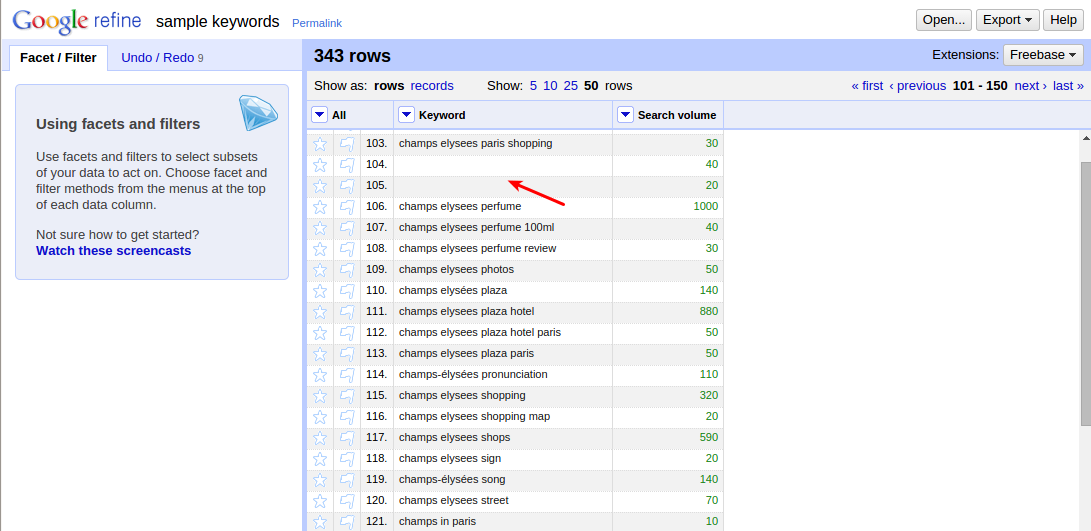
Předtím než řádky s prázdným klíčovým slovem odstraníme, je třeba hodnotu hledanosti přenést nahoru ke klíčovému slovu, ke kterému patří.
Nyní budeme pracovat se sloupcem hledanosti. Klikneme na modrou šipku a zvolíme “Edit cells -> Join multi-valued cells” (Editovat buňky -> Spojit buňky s více hodnotami).
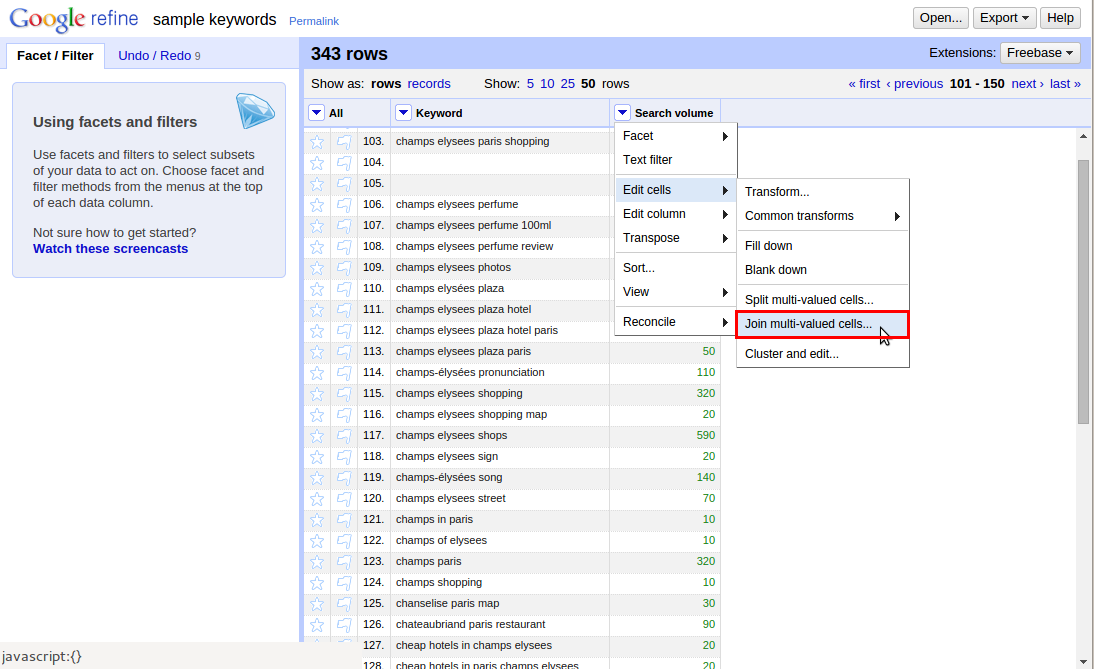
Vyskočí na nás dialogové okno s předvyplněnou čárkou. To jen potvrďte.
Nyní jsou duplicity pryč a u klíčových slov, které se sjednotili jsou všechny hodnoty hledanosti odděleny čárkou (např. 59, 68, 13).
S tím už si poradíme relativně snadno. Stačí u sloupce s hledaností opět kliknout na modrou šipku a zvolit “Edit cells -> Transform” (Editovat buňky -> Transformovat).
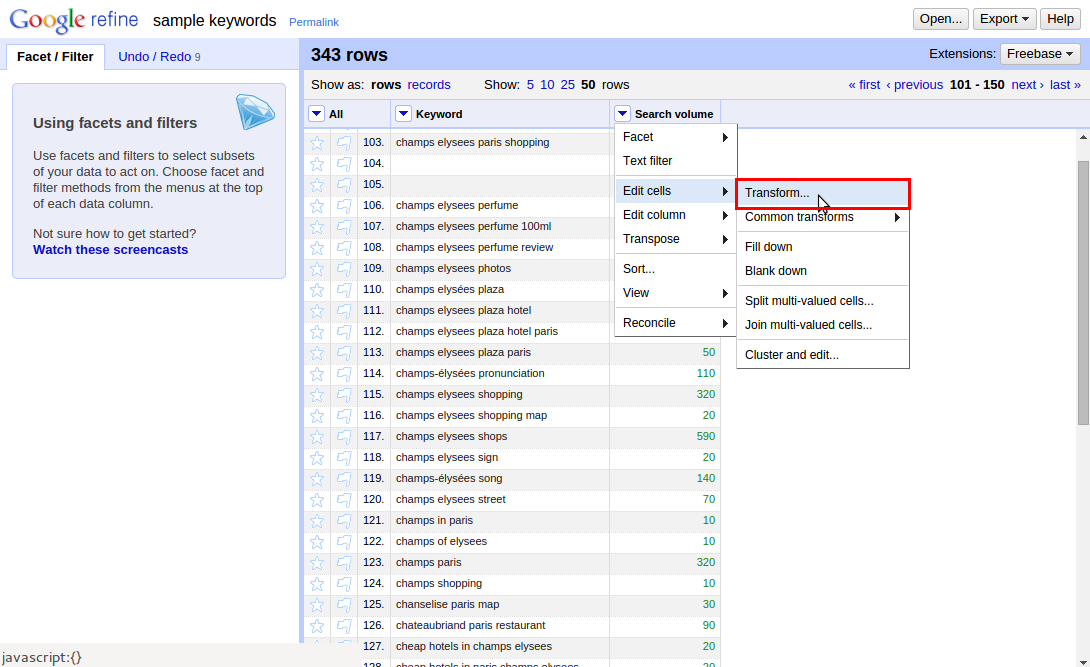
Do pole Expression jen vložte následující výraz:
forEach(value.split(','),v,v.toNumber()).sum()V náhledu, který se hned zobrazuje, můžete zkontrolovat, zdali se součet provedl správně.
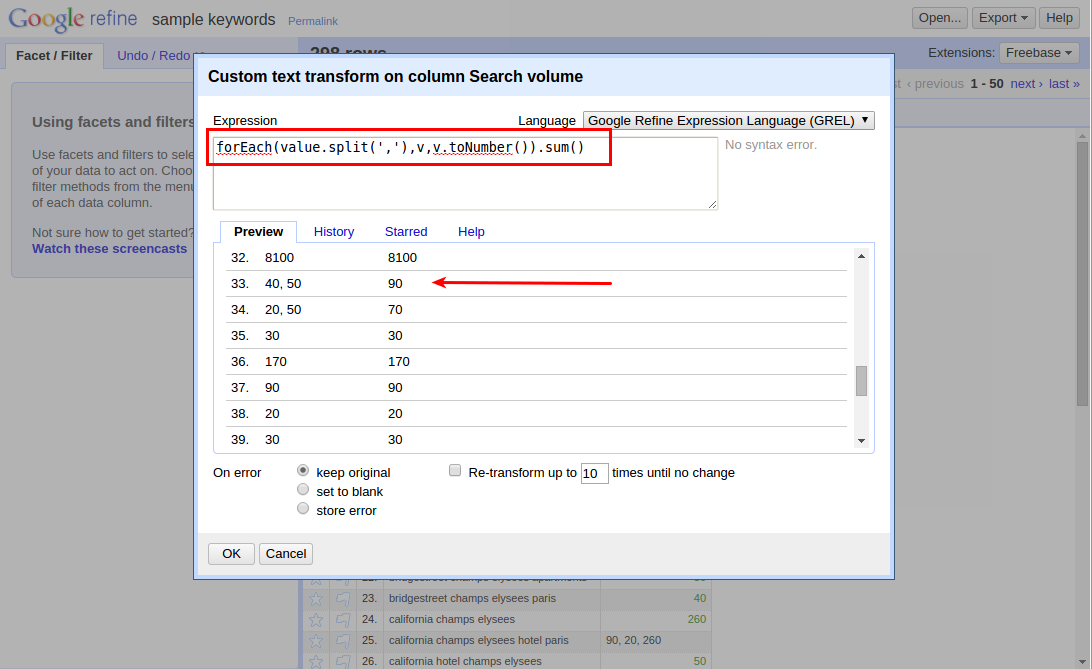
Hotovo! :-) Tlačítko “Export” vpravo nahoře vás z OpenRefine vysvobodí a můžete si pročištěná data otevřít třeba v Google Docs.
Tahák pro zapomnětlivé:
Duplicity:
- Místní nabídka slupce klíčových slov -> Sort -> řadit podle abecedy vzestupně
- Sort -> Reorder rows permanently
- Místní nabídka slupce klíčových slov -> Edit cells -> Blank down
- Místní nabídka slupce klíčových slov -> Facet -> Text facet
- Vpravo vybrat (blank)
- Místní nabídka prvního sloupce -> Edit rows -> Remowe all matching rows
Sjednocení klíčových slov:
- Místní nabídka slupce klíčových slov -> Edit cells -> Cluster and Edit
- Naklikat sjednocení -> Merge Selected & Re-Cluster
- Místní nabídka slupce klíčových slov -> Sort -> řadit podle abecedy vzestupně
- Sort -> Reorder rows permanently
- Místní nabídka slupce klíčových slov -> Edit cells -> Blank down
- Místní nabídka sloupce hledanosti -> Edit cells -> Join multi-valued cells -> nechat “, ” a dát OK
- Místní nabídka sloupce hledanosti -> Edit cells -> Transform
- Do Expression vyplnit:
forEach(value.split(','),v,v.toNumber()).sum() - OK
Odkazy
- Stáhnout OpenRefine (Google Refine)
- OpenRefine: Pomocník líného PPCčkaře, Karel Rujzl (slidy)
- Čistíme a tagujeme data pomocí Open Refine
- OpenRefine a report vyhledávacích dotazů
- Open Refine: vytvoření záznamu
- Foto návod: OpenRefine hostovaný u Google zdarma


Diskuze členů